
Is there a difference between understanding and memorising "something"? Absolutely. But does this still count for intelligent data extraction tools? Even more so.
In this IDP Insight post, we’ll explore how exactly to define these differences, and how they differentiate in the way they are able to process your document data.
Table of Content:
- Intelligent data extraction tools
- What do we mean?
- Examples
- How do data extraction tools process data?
- Define: Understanding data
- Define: Memorising data
- Which type is more important?
Intelligent data extraction tools: what do we mean?
Well, a data extraction tool itself is rather self-explanatory, no? It is a piece of technology that extracts data. But an intelligent data extraction tool is something more advanced. Here are some examples of them:
Data extraction examples:
- Basic/Non-Basic OCR (Optical Character Recognition)
- ICR (Intelligent Character Recognition)
- AI (Artificial Intelligence) and its subset ML (Machine Learning)
- IDP (Intelligent Document Processing)
How do data extraction tools process data?
Basic OCR:
By non-intelligent tools, we tend to refer to basic OCR that is the staple solution to extracting data – it essentially scans the document, creating somewhat of an image, and produces unstructured data output. This is not, however, a solution that is flexible or reliable – at least compared to intelligent counterparts.
Intelligent OCR (combined with AI):
Intelligent data extraction tools, that utilise AI, machine learning, or non-basic OCR, undergo a process that requires a few more steps from humans before they can successfully process document data.
The first step predominantly involves a human giving the tool ‘x amount’ of documents and manually telling the system where to extract data from. Then, the tools usually follow with these following steps:

Define: Understanding data
The following image shows a set of fruit. Now, if we follow the principle that a human will tell the system that these are pieces of fruit, and more specifically, that there’re: seven strawberries, three oranges, five pineapples, etc., then the data extraction tool will understand these details.

But this concept can only provide so much value to the user. It is valuable in the sense that the software understands the data as a human does, but if you show the tool another sample of the same fruit in a different layout, and do not give it any data, then it will not remember the information it previously understood.
So what?
Well, this means that users cannot automate this process if they need to extract data from various types of document formats (which is more often than you think). If the user values efficiency and ease, then this is not the direction to go.
Definition: Memorising data
Memorising without understanding is not learning, and understanding without memorising isn’t long-lived. You need both. But how do we define memorising data?
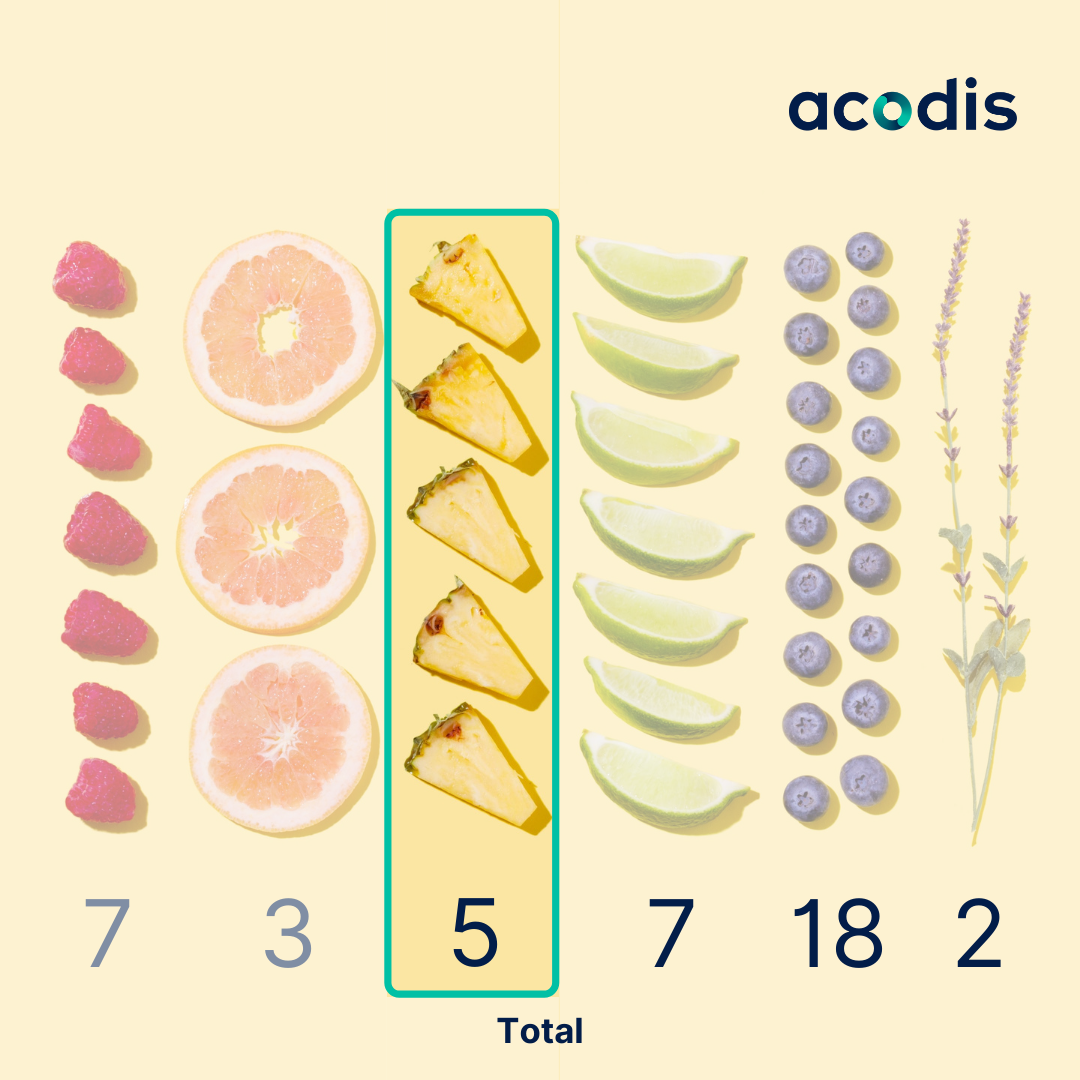
A system that is capable of memorising data will thus be able to identify that there are ‘x amount’ of fruit displayed, e.g., five pineapples, even if the document has an alternative layout. This level of capability is usually the consequence of systems with AI, and its subset, machine learning.
Which type is more important?
The short answer: memorising.
This is because, as we humans tend to be lazy, we look to opt for a solution that saves time and stress. When a data extraction tool can memorise document data, it ultimately removes the manual process from humans. It also constitutes the fact that the tool will be able to progressively grow smarter, being able to extract data more quickly/accurately over time. Merely understanding document data only serves the purpose for those looking to extract small pieces of document information, infrequently.
Talk to one of our Document Solution experts if your enterprise is looking for an intelligent data extraction tool that can understand and memorise data (and much more).

.png)

