Es ist kein Geheimnis. Der sprunghaft ansteigende Ansturm unstrukturierter Daten bringt Ihr Team um den Verstand. Diese Daten sind in E-Mails, Bildern und PDF-Dateien zu finden, doch ein Grossteil ihres Werts bleibt ungenutzt und wird nicht ausreichend verwendet.
Bislang waren viele wertvolle Erkenntnisse in Tabellen eingeschlossen, die überqualifizierte Mitarbeiter manuell suchen und extrahieren mussten.
Der Wert dieser ungenutzten Daten, in Verbindung mit dem zunehmenden Druck auf die Mitarbeitenden, hat die Technologie dazu gezwungen, sich weiterzuentwickeln.
Mithilfe von KI ermöglichen neue Entwicklungen im Bereich der optischen Zeichenerkennung (OCR) und der intelligenten Dokumentenverarbeitung (IDP) die automatische Entdeckung, Erkennung und Extraktion von Tabellen aus PDFs und Bildern.
Neu bei OCR und IDP?
Optische Zeichenerkennung (OCR) vs. Intelligente Dokumentenverarbeitung (IDP)
Inhaltsangabe:
- Wie die automatisierte Tabellenextraktion funktioniert
- Weshalb die automatisierte Tabellenextraktion aus PDFs eine Herausforderung ist
- Entwicklung und Unterschiede der Technologien zur Tabellenextraktion
- Vorteile der DL-gesteuerten Tabellenextraktion
Video: Tabellenextraktion
in 2 Minuten
Wie automatisierte Tabellenextraktion funktioniert
Schritt 1: Tabellen Entdeckung
Der Schritt der Tabellenentdeckung verwendet eine Kombination aus optischer Zeichenerkennung (OCR) und maschinellen Lernmodellen, um alle Tabellen in einer PDF-Datei oder einem Bild zu identifizieren.
Schritt 2: Tabellen Erkennung
Bei der Tabellenerkennung wird eine Kombination aus optischer Zeichenerkennung (OCR) und maschinellen Lernmodellen verwendet, um die Spalten, Zeilen und einzelnen Zellen aller Tabellen in einer PDF-Datei zu identifizieren.
Schritt 3: Tabellenextraktion
Der Schritt der Tabellen Extraktion verwendet eine Kombination aus optischer Zeichenerkennung (OCR) und maschinellen Lernmodellen, mit denen Sie ganze Tabellen aus Bildern und PDFs auswählen und für eine spätere Analyse extrahieren können.

Warum die automatisierte Tabellen Extraktion eine Herausforderung ist
-
Tabellen in derselben PDF-Datei können unterschiedliche Strukturen, Datentypen und inkonsistente Datenpunktpositionen aufweisen. Diese Varianten erschweren es regelbasierten und ML-basierten Ansätzen, Tabellen aus einer Vielzahl von PDFs zu extrahieren.
-
Tabellen haben selten identische Umrisse. Einige haben beispielsweise Begrenzungsrahmen, andere nicht, und wieder andere enthalten verschachtelte Zellen. Aufgrund dieser Unterschiede ist es für regelbasierte und ML-basierte Tabellenextraktion schwierig, genaue Ergebnisse zu erzielen.
-
Extrahierte Tabellen und Tabellendaten behalten nur selten ihren ursprünglichen Kontext und ihre hierarchische Struktur bei, so dass Mitarbeiter gezwungen sind, die extrahierten Tabellendaten neu zu strukturieren und den Kontext manuell hinzuzufügen.
-
Datenanalysten sind selten an der Analyse ganzer Tabellen interessiert, sondern suchen stattdessen nach spezifischen Tabellendaten, die sie zu eindeutigen Datensätzen für spätere Analysen zusammenstellen können.
Abbildung 1: Tabellenextraktion mit verschachtelten Zellen
Die Entwicklung der automatisierten Tabellen Extraktions-technologie
1. Regelbasierte Tabellenextraktion
Bei der vorlagenbasierten Tabellenextraktion wird eine Kombination aus optischer Zeichenerkennung (OCR) und regelbasierten Modellen verwendet, um die Entdeckung, Erkennung und Extraktion bestimmter Tabellen aus PDFs und Bildern zu automatisieren.
Regelbasierte Modelle können nicht als Einheitslösung für die Automatisierung der Tabellenextraktion verwendet werden. Geringfügige Abweichungen im Tabellenlayout (z. B. Tabellen ohne Begrenzungsrahmen) stellen ein grosses Problem für diesen Ansatz dar und machen ihn für die Mehrheit der Anwendungsfälle unbrauchbar.
2. ML-unterstützte Tabellenextraktion
Die ML-gestützte Tabellenxtraktion verwendet eine Kombination aus OCR und statistischen Machine-Learning-Modellen, um die Entdeckung, Erkennung und Extraktion ganzer Tabellen aus PDFs und Bildern zu automatisieren.
Das Hinzufügen von Machine Learning-Modellen zu regelbasierten Ansätzen ermöglicht die automatische Extraktion einer grösseren Vielfalt von Tabellentypen. Obwohl es sich noch immer nicht um eine skalierbare Lösung handelt, konnten ML-Modelle den Leerraum innerhalb einer randlosen Tabelle erkennen, messen und die Daten präzise extrahieren.
Die Herausforderung bei der ML-Tabellenextraktion bestand darin, dass Tabellen mit verschachtelten Zellen nicht genau erkannt und extrahiert werden konnten, und die meisten Tabellen enthalten verschachtelte Zellen. Eine weitere technologische Entwicklung war notwendig, um das Problem der automatisiertenTabellenextraktion endgültig zu lösen.
3. DL-gestützte Tabellenextraktion
Die DL-gestützte Tabellenxtraktion kombiniert Deep-Learning-Modelle mit OCR und Robotic Process Automation (RPA), um die Entdeckung, Erkennung und Extraktion ganzer und bestimmter Tabellendaten in grossen Mengen zu automatisieren. (z. B. bestimmte Tabellenzellen, -spalten oder -zeilen)
Das Hinzufügen von Deep-Learning-Modellen zu den beiden vorherigen Ansätzen führte zu einer massiven Verbesserung und ermöglichte die automatisierte Tabellenextraktion aus jeder beliebigen Tabelle, unabhängig von Layout oder Komplexität. Dieser Ansatz ist die einzige Option, die vollständig skalierbar, vielseitig und in jedem Anwendungsfall voll funktionsfähig ist.
Haben Sie Fragen zu Acodis IDP & Deep Learning?
Besuchen Sie: Datenextraktion mit maschinellem Lernen (ML)
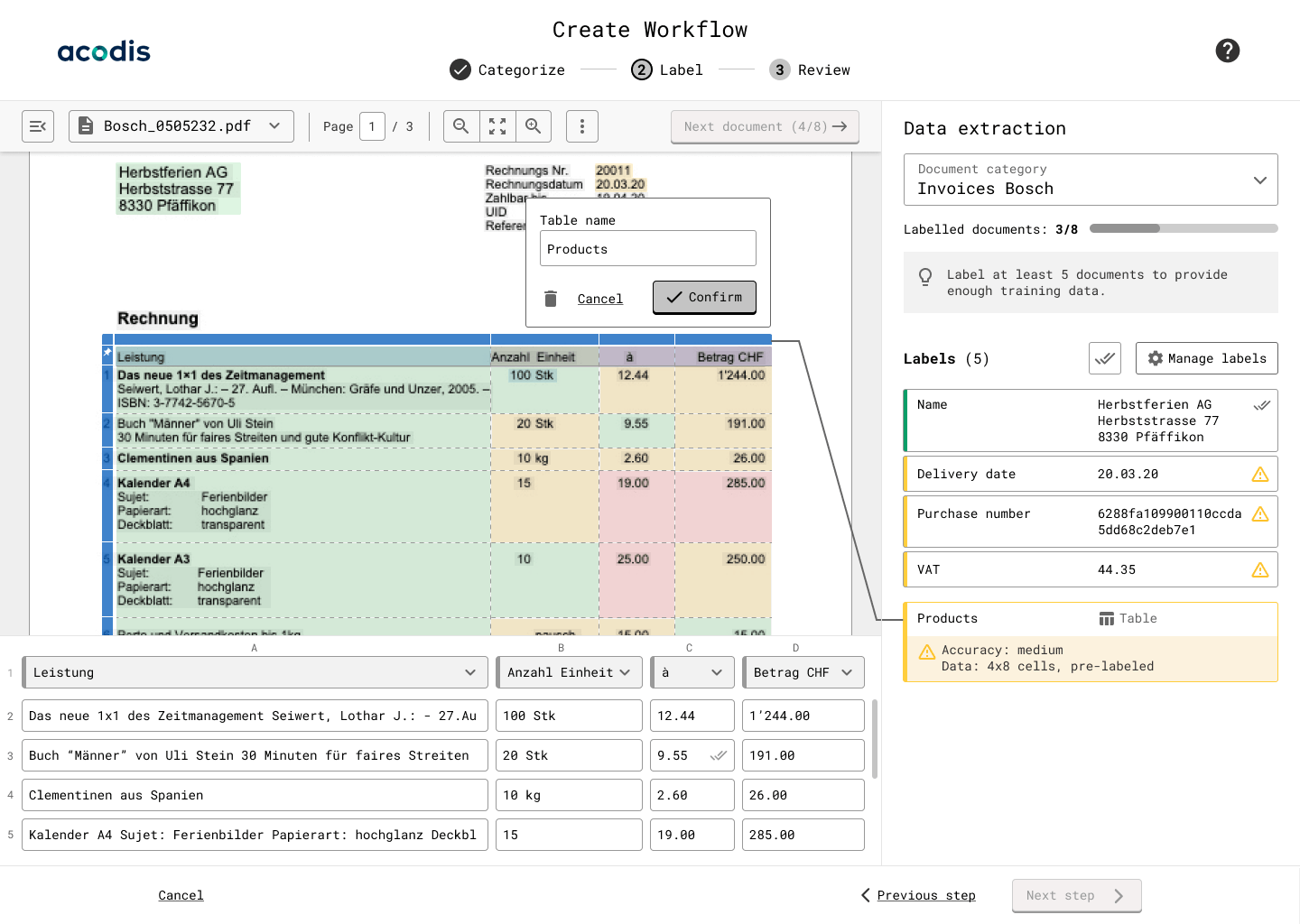 Abbildung 2: Acodis Tabellenextraktion basiert auf Deep-Learning-Modellen zur Extraktion ganzer und bestimmter Tabellendaten
Abbildung 2: Acodis Tabellenextraktion basiert auf Deep-Learning-Modellen zur Extraktion ganzer und bestimmter Tabellendaten
Vorteile der DL-gestützten Tabellenextraktion
- Sie können selbstverbessernde KI-Modelle mit Deep Learning trainieren, um spezifische Tabellendaten aus beliebigen PDFs oder Bildern in grossen Mengen zu isolieren und zu extrahieren. Es sind keinerlei Programmierkenntnisse erforderlich.
- Sie können die spezifischen Tabellendaten mit einer benutzerdefinierten kontextuellen Bedeutung versehen, bevor Sie sie in eine XML- oder JSON-Datei exportieren (das KI-Modell lernt auch, diese Funktion ohne Hilfe eines Benutzers auszuführen).
- Sie können benutzerdefinierte Validierungsparameter für bestimmte Tabellendaten festlegen. Das Deep-Learning-Modell prüft diese Daten vor dem Exportieren (z. B. eine Mindestlänge oder eine maximale Anzahl von Zeichen).
- Behalten Sie die ursprüngliche hierarchische Struktur und den Kontext der Tabellendaten bei.
- Diese Lösung funktioniert bei jeder Tabelle, unabhängig von Layout und Komplexität.
Sehen Sie die DL-gestützte Tabellenextraktion in Aktion
Vereinbaren Sie einen Termin für eine kostenlose Demo mit einem unserer Experten für Dokumentenlösungen und sehen Sie sich an, wie AI-Tabellenextraktion bei Ihren Dokumenten funktioniert.


