
It’s no secret. The skyrocketing influx of document and unstructured data is a daily pain for teams and a strategic roadblock for AI implementations. You can find valuable data in emails, images, and pdfs, yet much of its value is untapped and under-utilized.
Until now, many valuable insights were locked within table data that over-qualified staff needed to locate and extract manually.
The value of this unused data, coupled with the mounting pressure on every company’s workforce, has forced technology to evolve.
With the help of AI, new advancements within the Optical Character Recognition (OCR) and Intelligent Document Processing (IDP) space now enable automatic Table Detection, Table Recognition, and Table Extraction from PDFs and images.
New to OCR and IDP?
Optical Character Recognition (OCR) vs. Intelligent Document Processing (IDP)
Table of Content:
- How Automatic Table Extraction Works
- Why Automatic Table Extraction From PDFs is Challenging
- Evolution and Differences of Table Extraction Technologies
- Advantages of DL-Powered Table Extraction
Video: Table Extraction Explained in 2 Minutes
How Automatic Table Extraction Works
Step 1: Table Detection
The Table Detection step uses a combination of Optical Character Recognition (OCR) and machine learning models to identify all tables in any PDF or image.
Step 2: Table Recognition
The Table Recognition step uses a combination of Optical Character Recognition (OCR) and machine learning models to identify the columns, rows, and individual cells present in all tables in a PDF.
Step 3: Table Extraction
The Table Extraction step uses a combination of Optical Character Recognition (OCR) and machine learning models that allow you to select and extract whole tables from images and PDFs for later analysis.
Why Automatic Table Extraction is Challenging
- Tables on the same PDF can have varying structures, data types, and inconsistent data point locations. These variants make it difficult for template-based and ML-based approaches to extract tables from a diversity of PDFs.
- Tables rarely have identical outlines. For example, some have bounding boxes, some do not, and others include nested cells. These differences make it difficult for rule-based and ML-powered table extraction to reap accurate results.
- Extracted tables and table data rarely retain their original context and hierarchical structure, which forces staff to restructure extracted table data and add context manually.
- Data Analysts are rarely interested in analyzing whole tables but instead, look for specific table data they can compile into unique data sets for later analysis.
Figure 1: Table Extraction from Tables with Nested Cells
Evolution of Automatic Table Extraction Technology
1. Rule-Based Table Extraction
Template-based Table Extraction uses a combination of Optical Character Recognition (OCR) and rule-based models to automate the detection, recognition, and extraction of particular whole tables from PDFs and images.
Rule-based models could not be used as a one-size-fits-all solution to automating table extraction. Minor variances in table layouts (e,g, tables that don’t have bounding boxes) pose a major problem for this approach rendering it useless for the vast majority of use cases.
2. ML-Powered Table Extraction
ML-Powered Table Extraction uses a combination of OCR and statistical machine learning models to automate the detection, recognition, and extraction of whole tables in bulk from PDFs and images.
Adding Machine Learning models to rule-based approaches allowed the automatic extraction of a larger variety of table types. Though still not a scalable solution, ML models could identify and measure the whitespace within a borderless table and extract the data accurately.
The challenge for ML Table Extraction was its inability to recognize and extract tables that include nested cells accurately, and most tables include nested cells. Further technological evolution was necessary to solve the automatic table extraction problem more definitively.
3. DL-Powered Table Extraction
DL-Powered Table Extraction combines deep learning models with OCR, and Robotic Process Automation (RPA), to automate the detection, recognition, and extraction of whole and specific table data in bulk. (e.g., specific table cells, columns, or rows)
Adding deep learning models to the two previous approaches resulted in a giant leap forward and enabled automatic Table Extraction from any table, regardless of layout or complexity. This approach is the only option that is fully scalable, fully versatile, and fully functional in any use case.
Have questions about Acodis IDP & Deep Learning?
Visit: Data Extraction with Machine Learning
Schedule a meeting with one of our document solution experts.

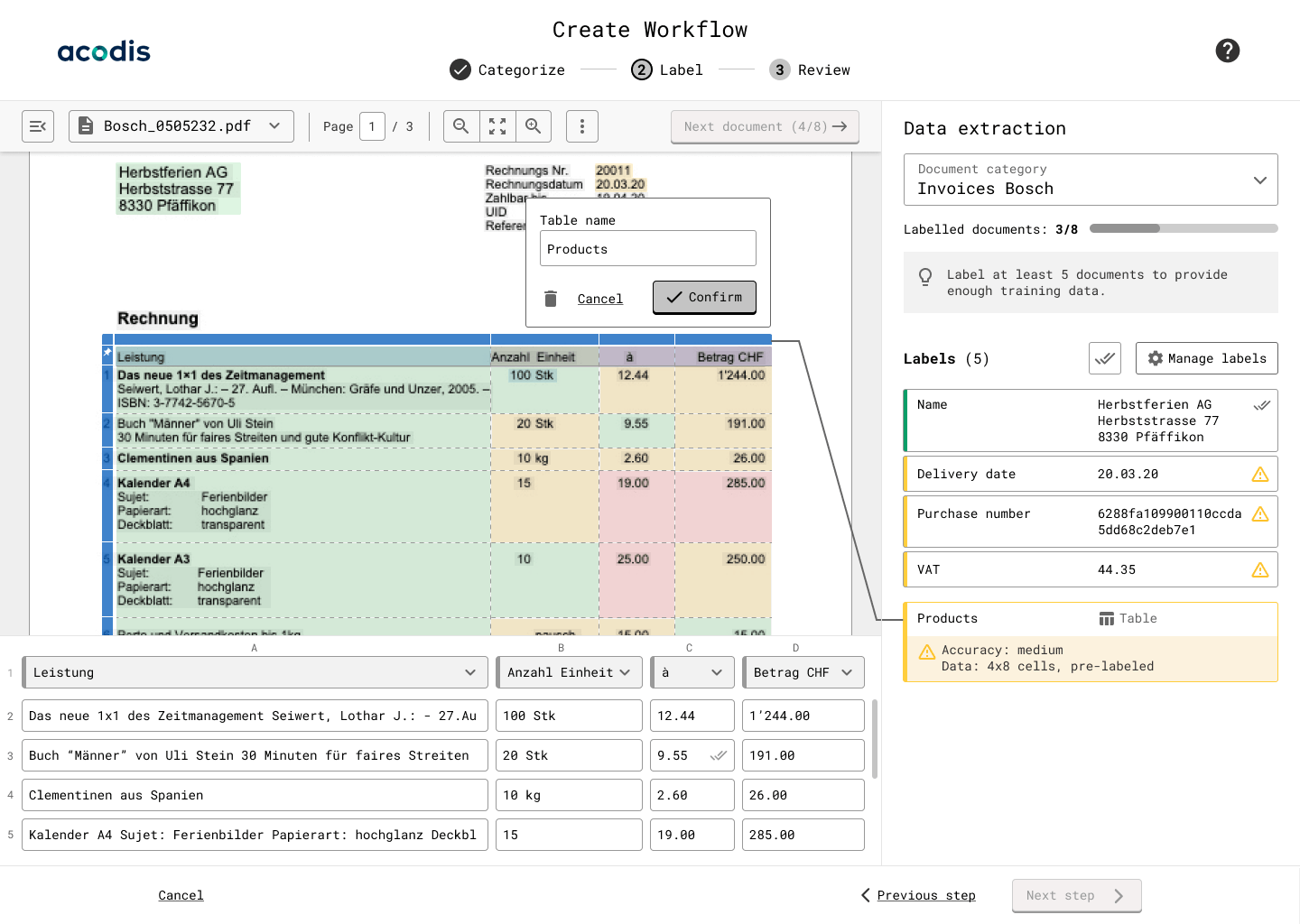 Figure 2: Acodis Table Extraction relies on deep learning models to extract whole and specific table data
Figure 2: Acodis Table Extraction relies on deep learning models to extract whole and specific table data
Advantages of DL-Powered Table Extraction
- You can train self-improving deep learning AI models to isolate and extract specific table data from any PDF or image in bulk. Zero coding skills are needed.
- You can annotate the specific table data with customized contextual meaning before exporting it into an XML or JSON file. (The AI model also learns to execute this function without a user’s help).
- You can set custom validation parameters for specific table data. The deep learning model cross-checks this data before exporting it. (e.g., minimum length value or a maximum number of characters).
- Retain the table data’s original hierarchical structure and context.
- This solution works on any table regardless of layout or complexity.
Schedule a meeting with one of our document solution experts.
.png)

.webp)